
seaborn 튜토리얼02 - Visualizing statistical relationships
Emphasizing continuity with line plots
scatter plot은 매우 효과적이지만, 언제나 사용할 수 있는 최적의 시각화 유형 같은 것은 없다. 시각적 표현은 데이터셋의 특성과 그림으로 답할 수 있는 질문에 맞게 조정해야 한다.
어떤 데이터셋을 가지고 한 변수의 변화를 시간의 함수나 유사하게 연속적인 변수로 이해하고 싶을 수도 있다. 이러한 상황에서는 line plot을 그리는 것이 좋다. seaborn에서는 lineplot() 함수를 사용하거나, kind=”line”로 설정한 relplot()으로 수행 할 수 있다.
df = pd.DataFrame(dict(time=np.arange(500),
value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()
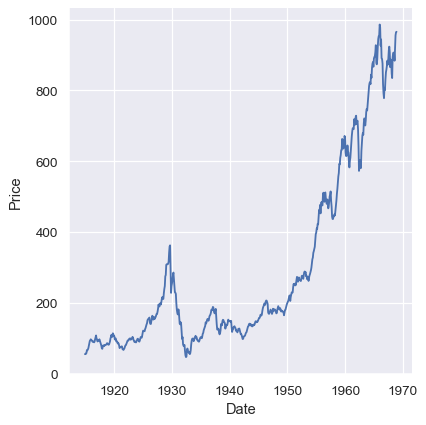
lineplot()은 y=f(x)를 그린다고 가정하므로, plot을 그리기 전에 x값을 기준으로 데이터를 정렬한다. 이 설정은 비활성화 할 수 있다.
df = pd.DataFrame(np.random.randn(500, 2).cumsum(axis=0), columns=["x", "y"])
sns.relplot(x="x", y="y", sort=False, kind="line", data=df);
Aggregation and representing uncertainty
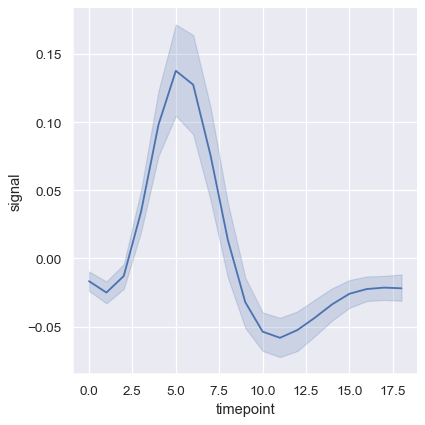
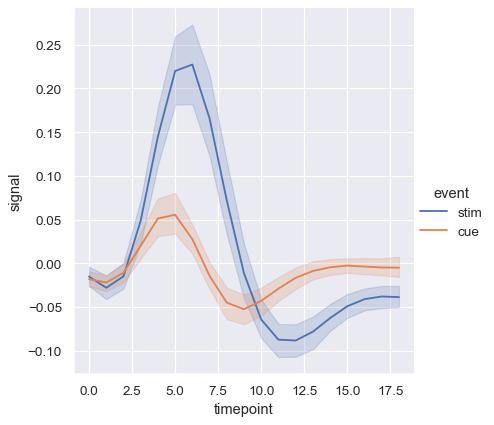
복잡한 데이터셋에는 동일한 x 변수 값에 대해 여러 측정 값이 있다. seaborn은 평균과 평균 주변의 95% 신뢰 구간을 나타내어 각 x값에서 여러 측정 값을 집계한다.
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint", y="signal", kind="line", data=fmri);
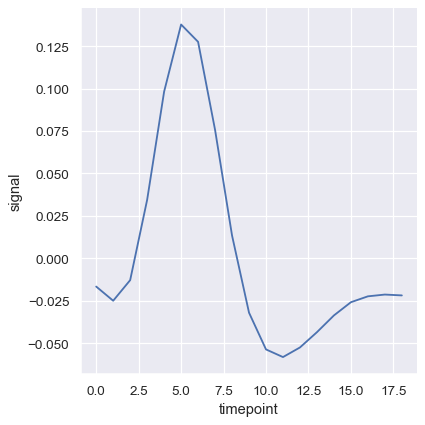
신뢰 구간은 bootstrapping을 사용하여 계산되며, 데이터셋이 큰 경우 시간이 많이 걸릴 수 있다. 신뢰 구간은 비활성화 할 수 있다.
sns.relplot(x="timepoint", y="signal", ci=None, kind="line", data=fmri);
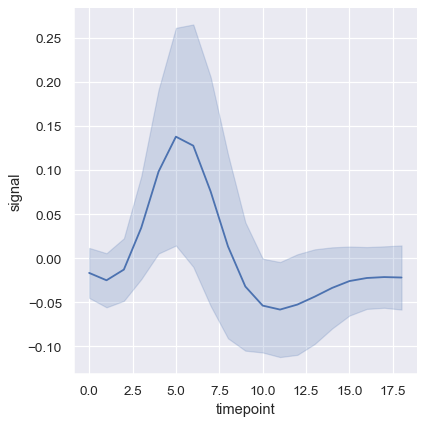
신뢰 구간 대신 표준 편차를 나타내어 각 timepoint에서 분포의 확산을 나타낼 수 있다.
sns.relplot(x="timepoint", y="signal", kind="line", ci="sd", data=fmri);
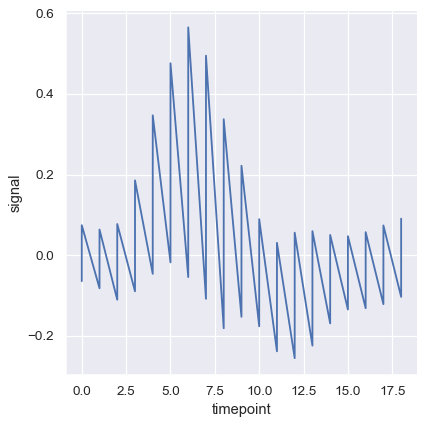
집계를 모두 끄려면 estimator=None으로 설정한다. 각 지점에서 데이터에 여러 관측치가 있는 경우 이상한 결과를 초래할 수 있다.
sns.relplot(x="timepoint", y="signal", estimator=None, kind="line", data=fmri);
Comments