
seaborn 튜토리얼01 - Visualizing statistical relationships
요약
- relplot으로 scatter plot과 line plot을 그릴 수 있다.(dafault값은 scatter)
- scatter plot은 2차원에서 그려지나, hue, style, size로 더 큰 차원을 표시할 수 있다.
- palette로 색상을 커스터마이즈 할 수 있다.
- sizes로 점의 크기를 커스터마이즈 할 수 있다.
Visualizing statistical relationships
통계 분석은 데이터셋의 변수가 어떻게 서로 관계되는지, 그리고 그러한 관계들이 다른 변수들에 어떻게 의존하는지 이해하는 프로세스이다. 시각화는 통계 분석의 핵심 구성 요소가 될 수 있다. 데이터가 올바르게 시각화되면, 인간의 시각 시스템이 관계를 나타내는 경향과 패턴을 볼 수 있기 때문이다.
이 튜토리얼에서는 세 가지 seaborn 함수에 대해 설명한다. 가장 많이 사용하는 것은 relplot()이다. 이는 scatter plot와 line plot이라는 두 가지 일반적인 접근 방식을 사용하여 통계적 관계를 시각화하는 figure-level function이다. relplot()은 FacetGrid를 다음 two axis-level function 중 하나와 결합한다.
- scatterplot() (with kind=”scatter”; the default)
- lineplot() (with kind=”line”)
앞으로 살펴 보겠지만, 이러한 함수는 복잡한 데이터셋 구조를 나타낼 수 있는 단순하고 이해하기 쉬운 데이터 표현을 사용하기 때문에 상당히 이해하기 쉽게 보여줄 수 있다. 색조(hue), 크기(size) 및 스타일(style)의 시맨틱을 사용하여 최대 3 개의 추가 변수를 매핑하여 2차원 도표를 그릴 수 있다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
Relating variables with scatter plots
scatter plot은 통계적 시각화의 주된 요소이다. 그것은 점들을 사용하여 두 변수의 공동 분포를 나타낸다. 각 점은 데이터셋의 관측치를 나타낸다. 이 묘사는 눈이 그들 사이에 의미있는 관계가 있는지에 대한 상당한 양의 정보를 유추 할 수 있게한다.
seaborn에서 scatter plot을 그리는 몇 가지 방법이 있다. 기본적으로, 두 변수가 모두 숫자 일 때 scatterplot()을 쓴다. categorical visualization tutorial에서는 scatter plot을 사용하여 categorical data를 시각화하기위한 특수한 도구를 볼 수 있다. scatterplot()은 relplot()의 kind 파라미터의 default 값으로 설정되어 있다. (kind=”scatter”로 직접 설정할 수 있다.)
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill", y="tip", data=tips);
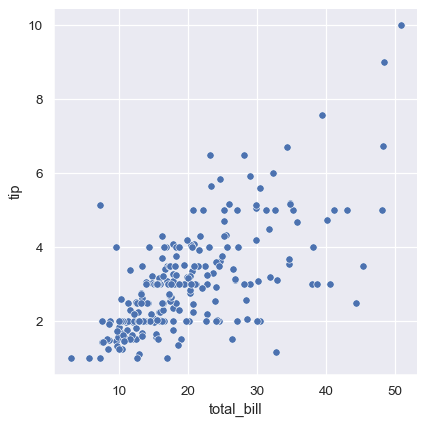
점은 2 차원으로 그려지는데, 세 번째 변수에 따라 점을 색칠하여 다른 차원을 플롯에 추가 할 수 있다. seaborn에서는 이를 “hue semantic”이라고 한다.
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips);
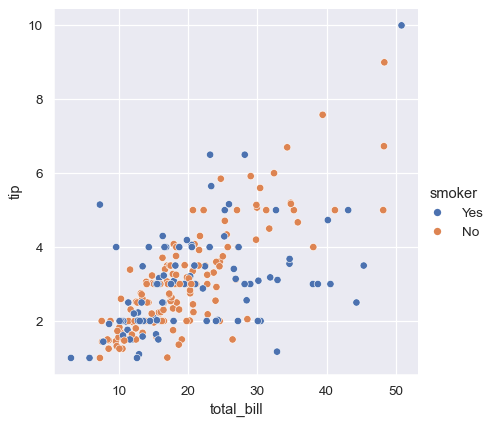
클래스 간의 차이점을 강조하고 접근성을 향상시키기 위해 각 클래스마다 다른 marker style을 사용할 수 있다.
sns.relplot(x="total_bill", y="tip", hue="smoker", style="smoker",
data=tips);
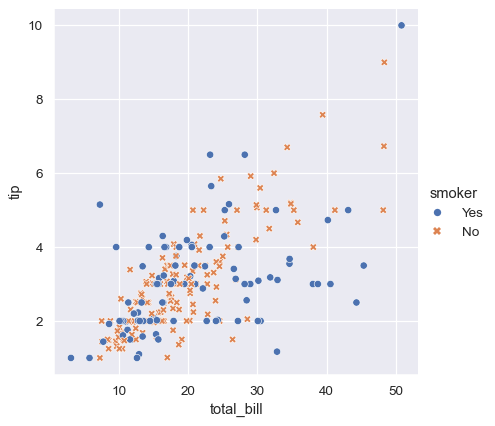
각 점의 hue와 style을 독립적으로 변경하여 네 가지 변수를 나타낼 수도 있다. 그러나 눈은 색보다 모양에 덜 민감하기 때문에 신중하게 수행해야 한다.
sns.relplot(x="total_bill", y="tip", hue="smoker", style="time", data=tips);
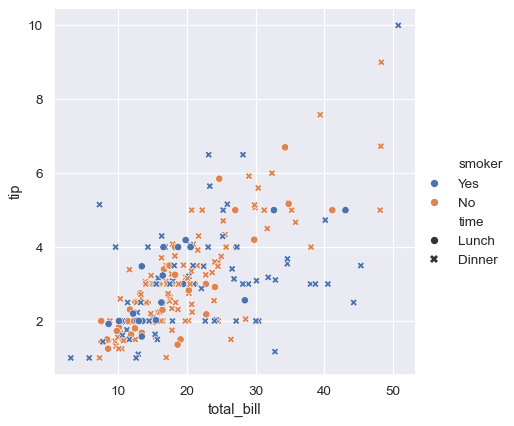
위의 예에서 hue semantic은 범주형이므로 default qualitative palette가 적용되었다. hue semantic이 숫자인 경우 (특히 float으로 캐스트 할 수있는 경우) 기본 색상은 sequential palette로 전환된다.
sns.relplot(x="total_bill", y="tip", hue="size", data=tips);
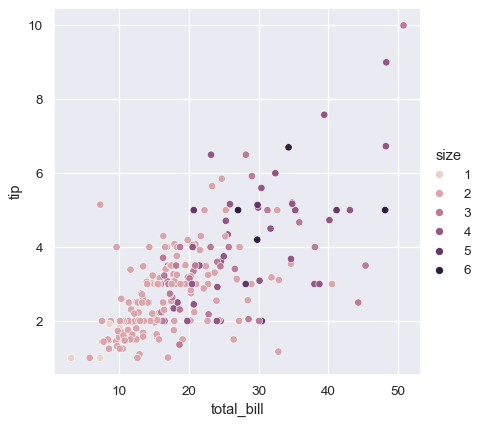
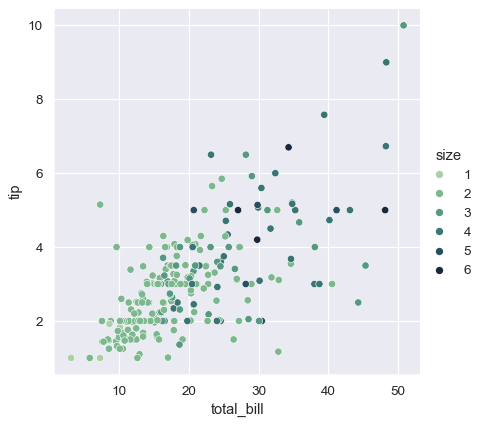
두 경우 모두 색상 팔레트를 사용자 정의 할 수 있다. 이를 위한 많은 옵션이 있다. 여기에서 string interface를 사용하여 cubehelix_palette()에 대한 sequential palette를 커스터마이즈한다.
sns.relplot(x="total_bill", y="tip", hue="size", palette="ch:r=-.5,l=.75", data=tips);
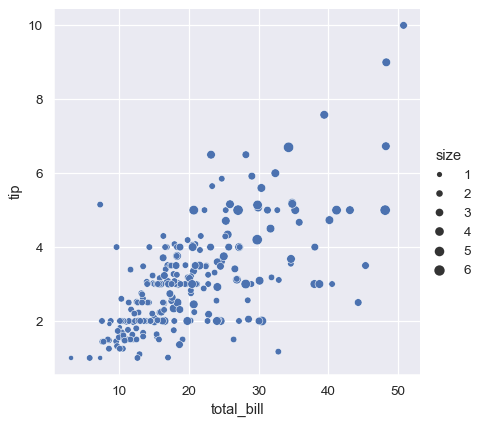
세 번째 종류의 시맨틱 변수는 각 점의 크기를 변경한다.
sns.relplot(x="total_bill", y="tip", size="size", data=tips);
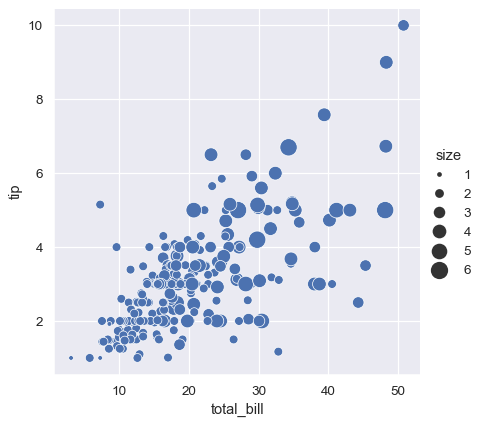
matplotlib.pyplot.scatter()와 달리 변수의 리터럴 값은 점의 영역을 선택하는데 사용되지 않는다. 대신, 데이터 단위의 값 범위는 영역 단위의 범위로 정규화된다. 이 범위는 커스터마이즈 할 수 있다.
sns.relplot(x="total_bill", y="tip", size="size", sizes=(15, 200), data=tips);
통계적 관계를 표시하기 위해 여러 시맨틱을 사용하는 방법을 사용자 정의하는 추가 예제는 scatterplot() API 예제에 표시되어 있다.
Comments